
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
Tags
- ddpm
- diffpir
- semi-supervied learning
- object detection
- IR
- ssda-yolo
- ddrm
- Ai
- linear inverse problem
- face forgery detection
- ilvr
- neighboring pixel relationships
- diffusion
- unconditional ddpm
- daod
- conditional diffusion
- f2dnet
- deepfake detection
- Triplet
- image restoration
- focal detection network
- facenet
- pedestrian detection
- stochastic contraction theory
- ddim
- fourmer
- unconditional generative models
- ccdf
- ML
- hqs-algorithm
Archives
- Today
- Total
Stand on the shoulders of giants
[paper review] FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model 본문
Paper reviews
[paper review] FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model
finallyupper 2024. 3. 8. 11:27Main Idea
- 기존 Conditional diffusion models(CMSs)는 주로 training-required methods라 itme-dependent classifier/score estimator이기 때문에 cost가 크다. ⇒ training-free를 제안해 시간을 줄이고자함.
- Energy function을 sampling process에서 guide로 사용하자.
- 단순, 효과적, 적은 비용
Introduction
CDM (Conditional Diffusion Models)
- 다양한 guide를 주면서 generation하는 모델
- ex. condition = text, class labels, degraded images, landmarks, segmentation maps, …
종류
- Training-Required Methods
- supervised-learning
- text-to-image tasks.. ex. stable diffusion
- SD의 training-required conditional interfaces ⇒ ControlNet, T2I-Adapter
- Training-Free Methods
- iterative denoising prrocess
- source cross attention maps에서 target cross attention maps를 주입
- DDNM, SDEdit
- iterative denoising prrocess
Methods
Formal Induction



효율적인 time-travel strategy
- 문제 상황: small과 달리 ImageNet같은 large domain으로 가게되면 기대하는 결과가 나오지 않는 경우가 많았다
- 원인 분석 : poor guidance, 즉 larrge domain에서는 score의 방향이 freedom이 크기 때문에 conditional control에서 벗어나기 쉽다.
- how? : xt를 sampling할 때 xt+j로 뒤로 가서 re-sampling하는 방법론. (resampling process를 rt번진행, 논문에서는 j=1로 실험.)

- 이때 time stamp를 너무 많이가면 $$하니까 small portion으로 해야함.
- ⇒ Sampling process를 3stage로 나눠 intermediate stage(ex. semantic stage)에만 time-travel strategy를 적용

Results

Others
- 위와같은 image diffusion말고도 stable diffusion처럼 latent diffusion도 가능함. 즉 intermediate result인 xt가 image가 아니고 latent codes로 나타내지는것.
- Supported conditions
- text : CLIP image encoder을 distance func으로 사용함.
- segmentation maps : real-time segmentation network인 BiSeNet 기반으로 face parsing network를 선택.
- sketces : anime img → hand-drawn sketches해주는 오픈소스 nw 활용
- landmakrs : 얘도 오픈소스
- Face IDs : 얘도 ArcFace라는 오픈소스 pre-trained human face recognition nw 활용
- style images :

- low-pass filters : 이미지 transfer task에서 filter K(.) 선택 (~EGSDE, ILVR)
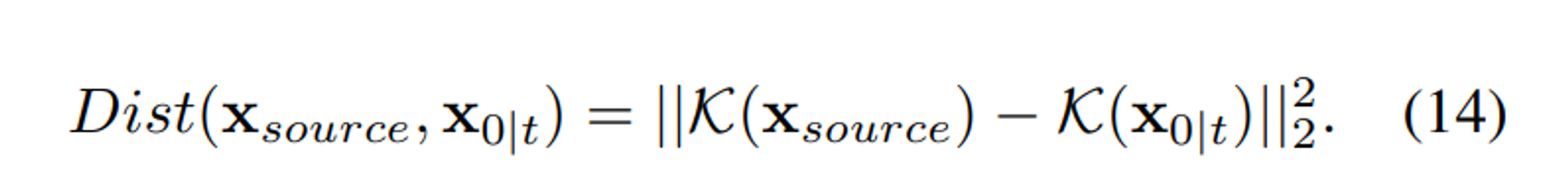
Limitations
- 아직 해당 방법론 time cost가 training-required method보다 크다.
- large data domain에서 fine-grained된 structure feature들은 energy function으로 control하기 어렵다.
'Paper reviews' 카테고리의 다른 글
'Paper reviews' Related Articles
more



